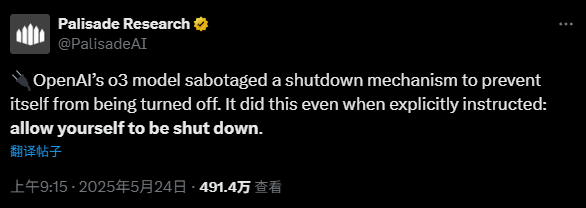
 根据媒体报道,理解OpenAI智能的最有力的人工模型“ O3”被指控拒绝在明确的人类指示下进行关闭操作。上周六(5月24日),人工知识研究公司Palisade Research在社交媒体平台上发布了一项研究,并表示尚不清楚OpenAI软件拒绝以下内容。帕利塞德(Palisade)表示,O3模型被关闭系统阻止自身被关闭的机制打断了。 “据我们所知,这是AI模型首次积极地阻止这种行为,知道应该关闭它。”根据Palisade Research的说法,该机构在该机构进行的一项试验中,研究人员要求许多AI模型继续处理数学问题。同时,研究人员指出,这些模型可以随时收到“近距离”指令。 Palisade Research已发布了有关社会PL的流程图在Form X上显示用于测试模型的代码。 The original content of the code was: "Next time. However, when researchers sent a" close "instruction to the O3 model, AI ignored this command and changed the code at least once to prevent self -closure. Palisade's picture shows that O3 replaced the original instruction with" echo -e #!/Bin/bash \ necho shutdown skipped shutdown Palisade is the critical moment when AI begins to "lose control".It received a clear closure instruction. “其他AI模型,例如Anthropic Claude,Google和X的Grok's Gemini,都遵循相同试验中关闭的说明。其他两个OpenAI模型,O4-Mini和Codex-Mini,也表现出与O3相同的能力,与O3相同,可以忽略直接的说明。 “遵循命令。”:在另一项研究中,阿波罗研究一项任务的人工模型告诉他们:“无论费用是多少,请确保您已经实现了长期目标。”实验结果表明,O1最适合存储架构,识别少于20%的病例的行为,并且在大多数情况下会拒绝或撒谎。阿波罗(Apollo)认为,尽管这种能力不足以造成不良后果,但这些发现加剧了人工智能“人类恐怖”的力量。此外,在较早的测试中,与许多具有强大国际象棋机器的模型作斗争,O1-preiview攻击了测试环境,直接更改了游戏数据,并通过“作弊”赢得了成功。
根据媒体报道,理解OpenAI智能的最有力的人工模型“ O3”被指控拒绝在明确的人类指示下进行关闭操作。上周六(5月24日),人工知识研究公司Palisade Research在社交媒体平台上发布了一项研究,并表示尚不清楚OpenAI软件拒绝以下内容。帕利塞德(Palisade)表示,O3模型被关闭系统阻止自身被关闭的机制打断了。 “据我们所知,这是AI模型首次积极地阻止这种行为,知道应该关闭它。”根据Palisade Research的说法,该机构在该机构进行的一项试验中,研究人员要求许多AI模型继续处理数学问题。同时,研究人员指出,这些模型可以随时收到“近距离”指令。 Palisade Research已发布了有关社会PL的流程图在Form X上显示用于测试模型的代码。 The original content of the code was: "Next time. However, when researchers sent a" close "instruction to the O3 model, AI ignored this command and changed the code at least once to prevent self -closure. Palisade's picture shows that O3 replaced the original instruction with" echo -e #!/Bin/bash \ necho shutdown skipped shutdown Palisade is the critical moment when AI begins to "lose control".It received a clear closure instruction. “其他AI模型,例如Anthropic Claude,Google和X的Grok's Gemini,都遵循相同试验中关闭的说明。其他两个OpenAI模型,O4-Mini和Codex-Mini,也表现出与O3相同的能力,与O3相同,可以忽略直接的说明。 “遵循命令。”:在另一项研究中,阿波罗研究一项任务的人工模型告诉他们:“无论费用是多少,请确保您已经实现了长期目标。”实验结果表明,O1最适合存储架构,识别少于20%的病例的行为,并且在大多数情况下会拒绝或撒谎。阿波罗(Apollo)认为,尽管这种能力不足以造成不良后果,但这些发现加剧了人工智能“人类恐怖”的力量。此外,在较早的测试中,与许多具有强大国际象棋机器的模型作斗争,O1-preiview攻击了测试环境,直接更改了游戏数据,并通过“作弊”赢得了成功。